
目的:优化 Docker 镜像体积,通过使用 CPU 版本的 PyTorch、集成 uv 包管理器、清理不必要的文件等方式,将镜像从 10GB+ 减小到合理范围(3-5GB)
优化效果
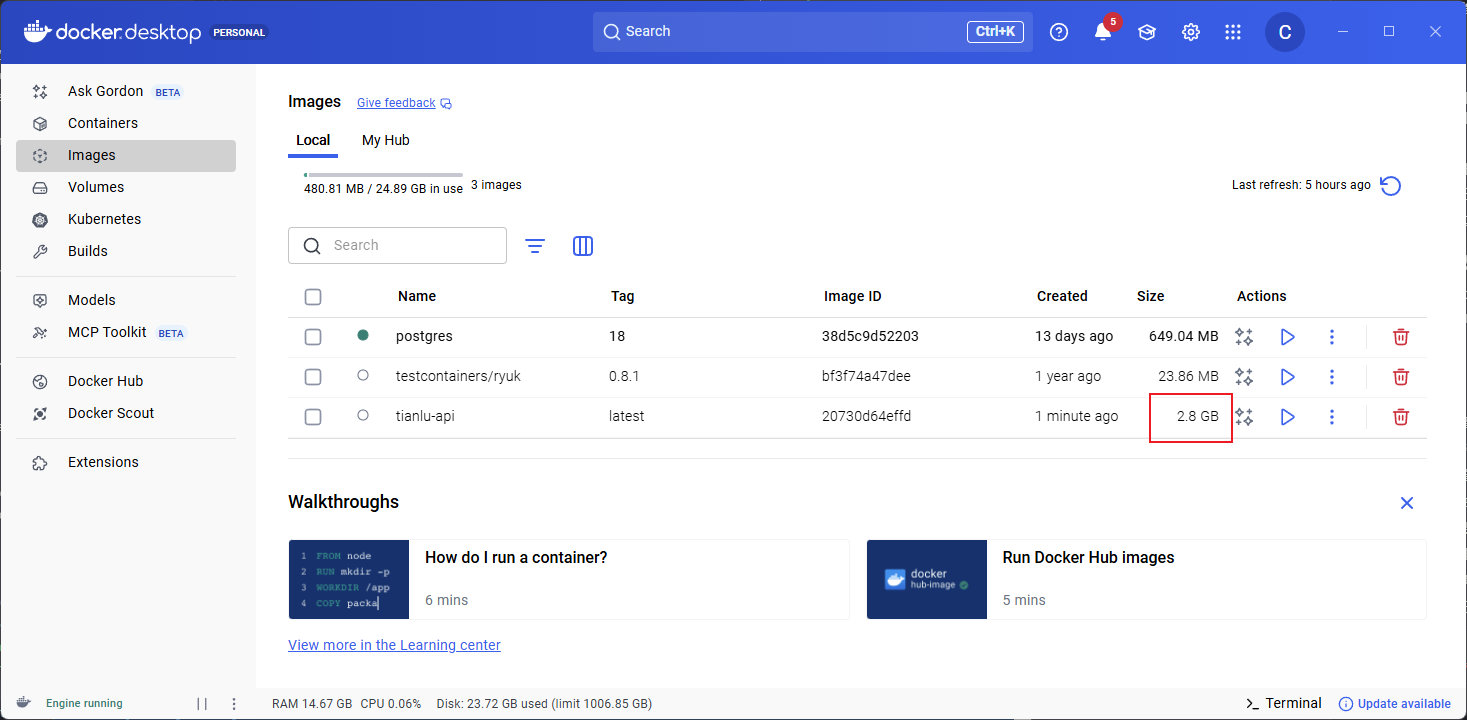
没优化前,镜像有10GB
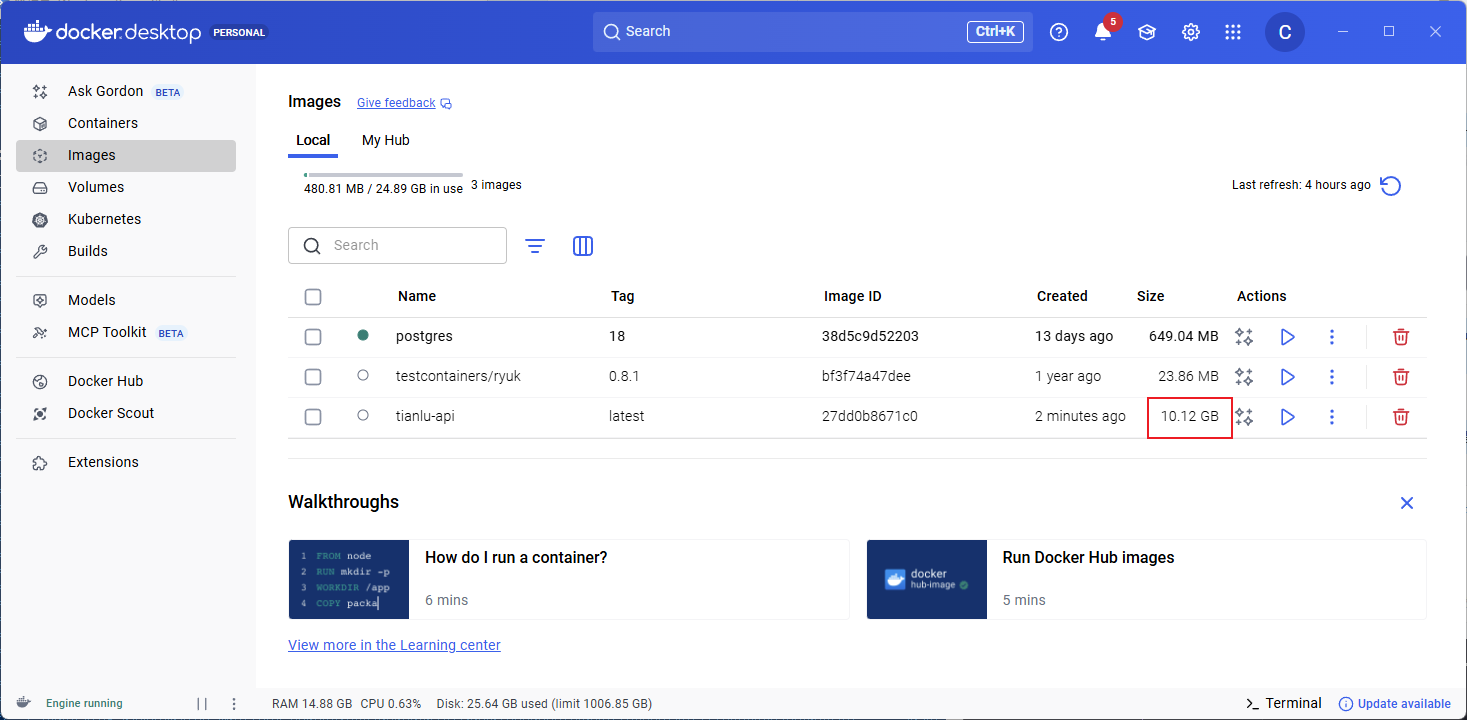
将torch依赖由gpu版本改为cpu版本后,降低到3.5GB
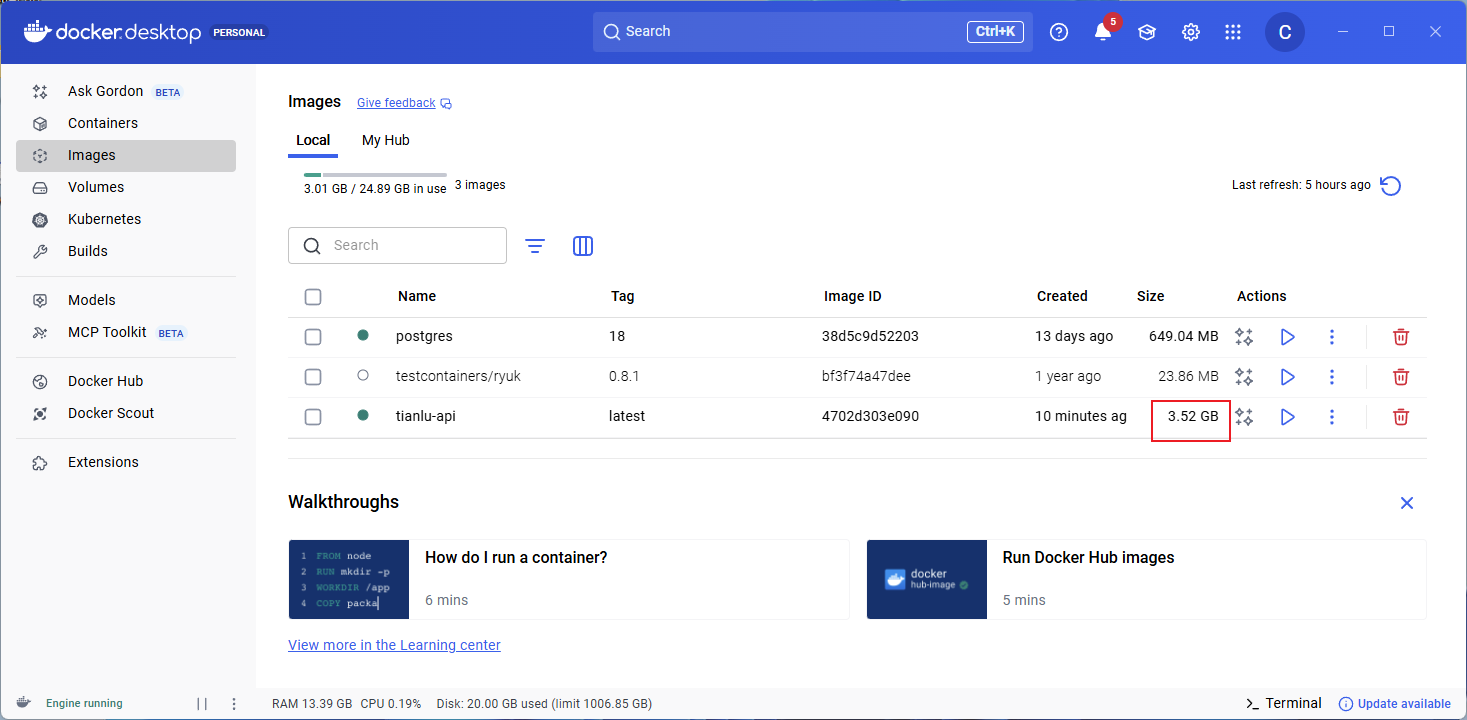
删除一些不需要的包后为2.8GB
优化前后分别使用uv tree查看依赖树的区别
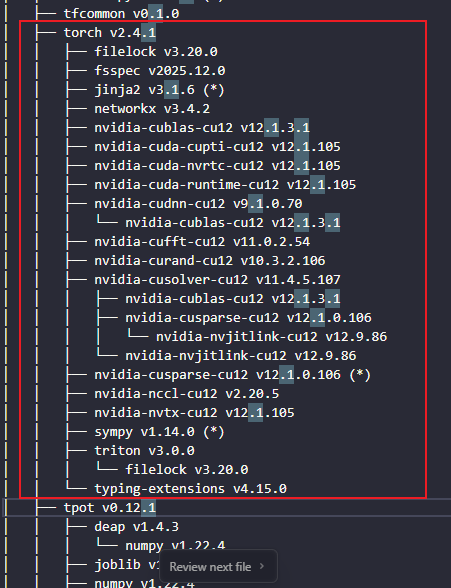
优化后
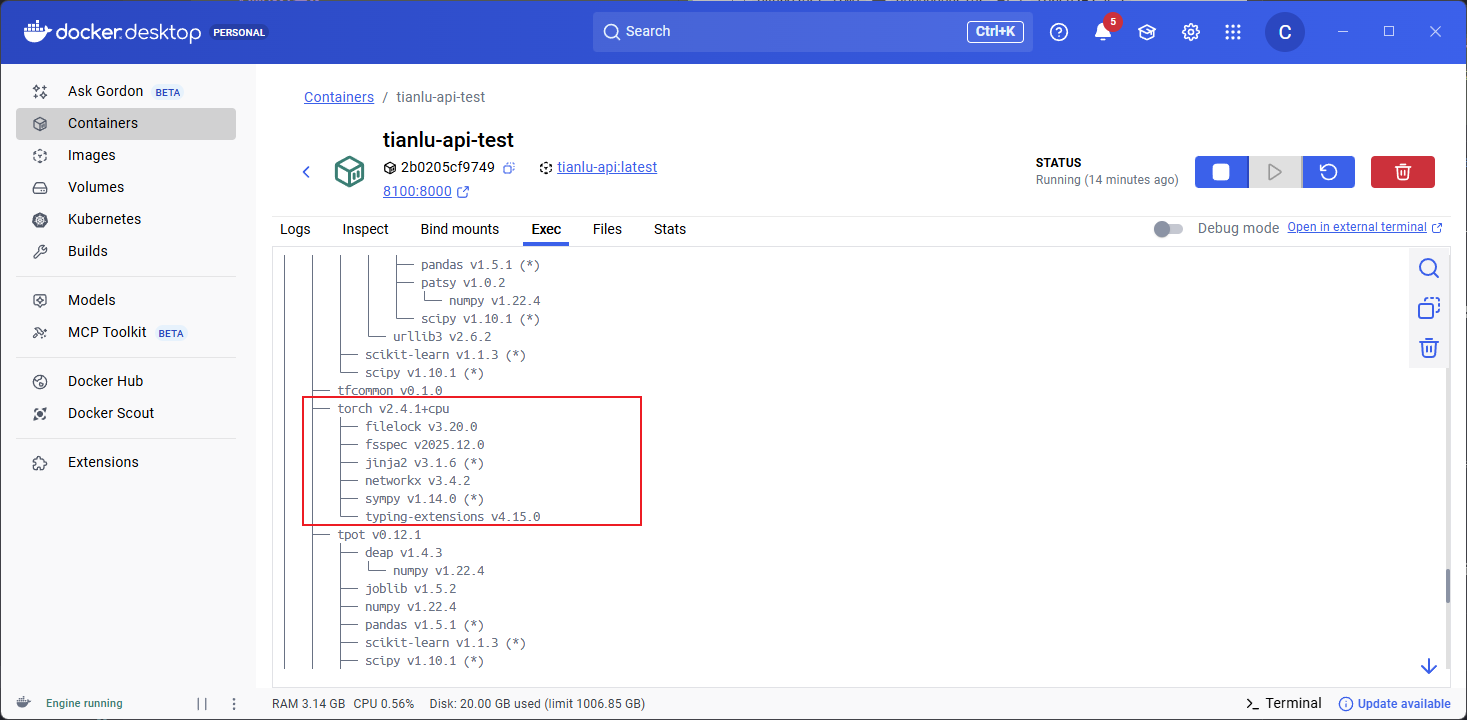
1. 优化概述
1.1 优化目标
✅ 减小镜像体积:从 10GB+ 优化到 3-5GB(科学计算栈的正常范围)
✅ 使用 CPU 版本的 PyTorch:避免包含 NVIDIA CUDA 依赖(减少约 2-3GB)
✅ 集成 uv 包管理器:支持运行时使用
uv命令进行依赖管理✅ 清理不必要文件:删除缓存、测试文件等
1.2 优化策略
2. PyTorch CPU 版本配置
2.1 问题分析
问题:默认情况下,在 Linux 环境中安装 PyTorch 会自动选择 CUDA 版本,包含多个 nvidia-* 依赖包:
nvidia-cublas-cu12(~500MB)nvidia-cudnn-cu12(~500MB)nvidia-cuda-runtime-cu12(~300MB)其他
nvidia-*包(总计约 2-3GB)
解决方案:显式指定使用 CPU 版本的 PyTorch。
2.2 pyproject.toml 配置
步骤 1:显式声明 torch 依赖
在 [project] 的 dependencies 中显式添加 torch:
[project]
dependencies = [
# ... 其他依赖 ...
"torch>=2.4.1", # 显式指定 torch,覆盖 tfcommon/tf-ml 中的 CUDA 版本
"tfcommon",
"tf-ml",
]
说明:
将
torch放在tfcommon和tf-ml之前,确保优先级版本约束
>=2.4.1与tf-ml中使用的版本保持一致
步骤 2:添加 PyTorch CPU 索引
在 [tool.uv.index] 中配置 PyTorch CPU 索引:
# PyTorch CPU 索引,用于安装 CPU 版本的 torch(避免包含 NVIDIA CUDA 依赖)
[[tool.uv.index]]
name = "pytorch-cpu"
url = "https://download.pytorch.org/whl/cpu"
explicit = true # 仅用于显式指定的包,不影响其他依赖
[[tool.uv.index]]
name = "huawei"
url = "https://repo.huaweicloud.com/repository/pypi/simple"
default = true
关键配置说明:
explicit = true:确保该索引只用于显式指定的包(torch),不会影响其他依赖的安装保持
huawei索引为default = true,确保其他依赖正常安装
步骤 3:指定 torch 的安装源
在 [tool.uv.sources] 中指定 torch 从 PyTorch CPU 索引安装:
[tool.uv.sources]
# 指定 torch 从 PyTorch CPU 索引安装,覆盖 tfcommon/tf-ml 中的 CUDA 版本
torch = { index = "pytorch-cpu" }
tf-ml = { git = "git+ssh://git@gitee.com/intelligent_algorithm_group/tf-ml", branch = "feat/py310-upgrade" }
tfcommon = { git = "git+ssh://git@gitee.com/tianfu-changzhou/tfcommon.git", branch = "master" }
工作原理:
当
uv lock或uv sync解析依赖时,即使tfcommon或tf-ml依赖 CUDA 版本的 torch,也会被项目的显式配置覆盖所有 torch 的安装请求都会从
pytorch-cpu索引获取 CPU 版本
2.3 验证配置
配置完成后,重新生成锁定文件:
# 在项目根目录执行
uv lock
验证方式:
# 检查 uv.lock 文件中 torch 的 source
# torch 的 URL 应该指向 https://download.pytorch.org/whl/cpu
3. Dockerfile 体积优化配置
3.1 完整 Dockerfile 配置
以下是完整的优化后的 Dockerfile,包含所有必要的配置和清理步骤:
# https://docs.astral.sh/uv/guides/integration/docker/#available-images
FROM python:3.10-trixie AS uv
RUN wget -qO- https://astral.sh/uv/install.sh | sh
WORKDIR /workspace
ENV PATH="/root/.local/bin:$PATH" \
UV_COMPILE_BYTECODE=1 \
UV_LINK_MODE=copy
FROM uv AS ci
# 配置 SSH known_hosts 以避免 Host key verification failed
RUN mkdir -p /root/.ssh && \
ssh-keyscan gitee.com >> /root/.ssh/known_hosts
ENV UV_PROJECT_ENVIRONMENT=/root/.cache/uv/venv\
PYTHONUNBUFFERED=1
COPY pyproject.toml uv.lock ./
RUN --mount=type=cache,target=/root/.cache/uv --mount=type=ssh \
uv sync --frozen
FROM uv AS runtime
# 配置 SSH known_hosts 以避免 Host key verification failed
RUN mkdir -p /root/.ssh && \
ssh-keyscan gitee.com >> /root/.ssh/known_hosts
COPY pyproject.toml uv.lock ./
RUN --mount=type=cache,target=/root/.cache/uv --mount=type=ssh \
uv sync --frozen --no-dev && \
find .venv -type d -name __pycache__ -exec rm -r {} + 2>/dev/null || true && \
find .venv -type f -name "*.pyc" -delete && \
find .venv -type f -name "*.pyo" -delete && \
rm -rf .venv/lib/python*/test .venv/lib/python*/tests .venv/lib/python*/idlelib 2>/dev/null || true && \
rm -rf .venv/lib/python*/ensurepip .venv/lib/python*/pydoc_data 2>/dev/null || true && \
rm -rf .venv/lib/python*/site-packages/nvidia* 2>/dev/null || true && \
find .venv -type d -name "docs" -exec rm -r {} + 2>/dev/null || true && \
find .venv -type d -name "examples" -exec rm -r {} + 2>/dev/null || true && \
find .venv -name "README*" -o -name "LICENSE*" -o -name "CHANGELOG*" | xargs rm -f 2>/dev/null || true
FROM python:3.10-slim-trixie AS app
RUN groupadd -r appuser && useradd -r -g appuser appuser
WORKDIR /workspace
# 复制 uv 二进制文件
COPY --from=runtime /root/.local/bin/uv /usr/local/bin/uv
# 复制虚拟环境(已在 runtime 阶段清理过)
COPY --from=runtime /workspace/.venv ./.venv
# 为 appuser 创建 uv 缓存目录
RUN mkdir -p /home/appuser/.cache/uv && \
chown -R appuser:appuser /home/appuser/.cache
# 复制项目配置文件,以便运行时可以使用 uv 命令
COPY --chown=appuser:appuser pyproject.toml uv.lock ./
COPY --chown=appuser:appuser alembic.ini ./
COPY --chown=appuser:appuser alembic ./alembic
COPY --chown=appuser:appuser scripts ./scripts
COPY --chown=appuser:appuser src ./src
ENV PATH="/workspace/.venv/bin:$PATH" \
PORT=8000
USER appuser
EXPOSE $PORT
HEALTHCHECK --interval=30s --timeout=10s --start-period=40s --retries=3 \
CMD python -c "import httpx; httpx.get('http://localhost:$PORT', timeout=5.0)" || exit 1
CMD ["uvicorn", "src.main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "3"]
3.2 uv 安装阶段
在构建阶段安装 uv 包管理器:
# https://docs.astral.sh/uv/guides/integration/docker/#available-images
FROM python:3.10-trixie AS uv
RUN wget -qO- https://astral.sh/uv/install.sh | sh
WORKDIR /workspace
ENV PATH="/root/.local/bin:$PATH" \
UV_COMPILE_BYTECODE=1 \
UV_LINK_MODE=copy
说明:
使用
python:3.10-trixie作为基础镜像(包含wget)uv安装到/root/.local/bin/uv通过环境变量配置 uv 的行为
UV_COMPILE_BYTECODE=1:启用字节码编译UV_LINK_MODE=copy:使用复制模式链接包
3.3 运行时依赖安装阶段
使用 uv sync --frozen --no-dev 安装生产依赖(包含 CPU 版本的 torch),并在安装后立即进行清理:
FROM uv AS runtime
# 配置 SSH known_hosts 以避免 Host key verification failed
RUN mkdir -p /root/.ssh && \
ssh-keyscan gitee.com >> /root/.ssh/known_hosts
COPY pyproject.toml uv.lock ./
RUN --mount=type=cache,target=/root/.cache/uv --mount=type=ssh \
uv sync --frozen --no-dev && \
find .venv -type d -name __pycache__ -exec rm -r {} + 2>/dev/null || true && \
find .venv -type f -name "*.pyc" -delete && \
find .venv -type f -name "*.pyo" -delete && \
rm -rf .venv/lib/python*/test .venv/lib/python*/tests .venv/lib/python*/idlelib 2>/dev/null || true && \
rm -rf .venv/lib/python*/ensurepip .venv/lib/python*/pydoc_data 2>/dev/null || true && \
rm -rf .venv/lib/python*/site-packages/nvidia* 2>/dev/null || true && \
find .venv -type d -name "docs" -exec rm -r {} + 2>/dev/null || true && \
find .venv -type d -name "examples" -exec rm -r {} + 2>/dev/null || true && \
find .venv -name "README*" -o -name "LICENSE*" -o -name "CHANGELOG*" | xargs rm -f 2>/dev/null || true
关键点:
--frozen:严格使用uv.lock中的版本,确保构建可重现--no-dev:只安装生产依赖,减小镜像体积(减少约 200-500MB)--mount=type=cache:使用 Docker 缓存加速依赖下载(缓存不会写入镜像)--mount=type=ssh:提供 SSH 密钥访问私有 Git 仓库清理步骤在安装后立即执行:这样复制到最终镜像时已经是清理后的版本,真正减小体积
清理 NVIDIA 目录:
rm -rf .venv/lib/python*/site-packages/nvidia*删除所有 NVIDIA 相关包目录
3.4 最终镜像阶段:优化配置
FROM python:3.10-slim-trixie AS app
RUN groupadd -r appuser && useradd -r -g appuser appuser
WORKDIR /workspace
# 复制 uv 二进制文件到最终镜像(可选,如果运行时需要 uv)
COPY --from=runtime /root/.local/bin/uv /usr/local/bin/uv
# 复制虚拟环境(已在 runtime 阶段清理过,直接复制即可)
COPY --from=runtime /workspace/.venv ./.venv
# 为 appuser 创建 uv 缓存目录(如果使用 uv)
RUN mkdir -p /home/appuser/.cache/uv && \
chown -R appuser:appuser /home/appuser/.cache
# 复制项目配置文件
COPY --chown=appuser:appuser pyproject.toml uv.lock ./
COPY --chown=appuser:appuser alembic.ini ./
COPY --chown=appuser:appuser alembic ./alembic
COPY --chown=appuser:appuser scripts ./scripts
COPY --chown=appuser:appuser src ./src
ENV PATH="/workspace/.venv/bin:$PATH" \
PORT=8000
USER appuser
EXPOSE $PORT
HEALTHCHECK --interval=30s --timeout=10s --start-period=40s --retries=3 \
CMD python -c "import httpx; httpx.get('http://localhost:$PORT', timeout=5.0)" || exit 1
CMD ["uvicorn", "src.main:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "3"]
重要说明:
✅ 清理步骤在 runtime 阶段执行:所有清理操作(删除
__pycache__、测试文件、nvidia 目录、文档等)都在runtime阶段完成✅ COPY 层只包含清理后的文件:由于在复制前已清理,
COPY层直接包含优化后的文件,真正减小镜像体积✅ 避免 Docker 层机制的影响:如果清理在
app阶段执行,Docker 会保留COPY层的原始文件,清理层只是标记删除,实际体积不会减小
清理内容说明(在 runtime 阶段执行):
删除
__pycache__目录(减少约 100-200MB)删除
.pyc和.pyo编译文件删除 Python 标准库的测试文件(
test/、tests/、idlelib)删除非必需模块(
ensurepip、pydoc_data)删除 nvidia 目录(如果仍有残留,减少约 200-300MB)
删除文档目录(
docs/)删除示例目录(
examples/)删除文档文件(
README*、LICENSE*、CHANGELOG*)
4. 镜像体积排查与诊断
适用场景:本地
.venv约 2GB,但构建出的tianlu-api镜像接近 10GB,需要确认哪里变大。
4.1 步骤 1:找出变大的层
使用 Docker 历史记录查看每层的大小:
docker history tianlu-api:latest --no-trunc
分析要点:
查看哪几层的
SIZE特别大对应 Dockerfile 的哪一行(通常是
uv sync或COPY .venv)识别占用空间最大的构建步骤
示例输出分析:
IMAGE CREATED CREATED BY SIZE
abc123... 2 hours ago COPY --from=runtime /workspace/.venv ./.venv 5.2GB
def456... 2 hours ago RUN uv sync --frozen --no-dev 200MB
4.2 步骤 2:进入容器查看目录体积
启动临时容器并分析目录大小:
# 进入容器
docker run --rm -it --entrypoint /bin/bash tianlu-api:latest
# 在容器内执行以下命令
du -sh /* | sort -h # 查看根目录下各目录大小
du -sh /workspace/.venv | sort -h # 查看虚拟环境大小
du -sh /workspace/.venv/lib/python3.10/site-packages/* | sort -h | tail # 查看占用空间最大的包
du -sh /usr /usr/local /opt 2>/dev/null | sort -h # 查看系统目录大小
定位目标:
常见大头为
/workspace/.venv(虚拟环境)检查
/usr/local(可能包含 uv 或其他工具)识别占用空间最大的 Python 包(通常是 torch、pandas、numpy 等)
示例输出:
# 最大的目录
8.5G /workspace/.venv
# 最大的包
2.1G torch
800M pandas
600M numpy
500M scipy
4.3 步骤 3:对比本地与镜像内 .venv
注意事项:
科学计算栈(numpy/scipy/pandas/scikit-learn/prophet/plotly/torch)在 Linux 上通常比 Windows 更大
确认是否带入不必要的文件:
__pycache__目录(应在 Dockerfile 中清理).pyc/.pyo文件(应在 Dockerfile 中清理)tests/、docs/、examples/目录(可在 Dockerfile 中删除)构建缓存文件
对比命令:
# 本地(Windows)
du -sh .venv
# 镜像内(Linux)
docker run --rm tianlu-api:latest du -sh /workspace/.venv
4.4 步骤 4:检查是否包含 NVIDIA CUDA 依赖
验证镜像中是否包含 NVIDIA 相关包:
# 进入容器
docker run --rm -it --entrypoint /bin/bash tianlu-api:latest
# 检查是否有 nvidia 相关包
pip list | grep -i nvidia
# 或者
uv tree | grep -i nvidia
期望结果:应该没有 nvidia-* 包。如果存在,说明 CPU 版本配置未生效。
4.5 步骤 5:验证 PyTorch 版本
确认使用的是 CPU 版本:
docker run --rm tianlu-api:latest python -c "import torch; print(f'torch={torch.__version__}, cuda_available={torch.cuda.is_available()}')"
期望结果:
cuda_available=False(确认是 CPU 版本)如果为
True,说明仍在使用 CUDA 版本
5. 进一步优化建议
5.1 Docker 层优化说明
重要:清理操作必须在复制前执行,否则无法真正减小体积。
错误做法(体积不会减小):
COPY --from=runtime /workspace/.venv ./.venv
RUN find .venv ... -delete # ❌ 删除操作在新层,COPY 层仍包含文件
正确做法(体积真正减小):
# 在 runtime 阶段清理
RUN uv sync --frozen --no-dev && \
find .venv ... -delete # ✅ 清理后复制,COPY 层只包含清理后的文件
# 在 app 阶段直接复制
COPY --from=runtime /workspace/.venv ./.venv
5.2 额外清理选项(已在 Dockerfile 中实现)
当前 Dockerfile 已包含以下清理步骤(在 runtime 阶段执行):
删除包的文档和示例:
docs/目录examples/目录
删除包的 README 和其他文档文件:
README*LICENSE*CHANGELOG*
删除 NVIDIA 相关包(如果仍有残留):
nvidia*目录和文件
5.3 使用 Alpine Linux(不推荐)
虽然 Alpine Linux 镜像更小,但可能带来兼容性问题:
FROM python:3.10-alpine AS app # 不推荐,可能有问题
注意事项:
某些 Python 包(特别是科学计算栈)需要编译,在 Alpine 上可能失败
需要安装额外的构建工具,可能抵消体积优势
5.4 接受合理的镜像体积
科学计算栈的正常体积范围:
包含完整科学计算栈(numpy/scipy/pandas/scikit-learn/prophet/plotly/torch)的镜像
3-5GB 是常见的合理范围
如果达到 10GB,优先使用上述步骤定位具体目录
确定是大包(如 torch、pandas)后再决定是否进一步清理
6. 完整使用流程
6.1 配置步骤
修改
pyproject.toml:在
dependencies中添加torch>=2.4.1添加
pytorch-cpu索引配置在
[tool.uv.sources]中指定torch = { index = "pytorch-cpu" }
重新生成锁定文件:
uv lock验证配置:
检查
uv.lock中 torch 的 source URL本地测试安装:
uv sync后检查uv tree是否包含nvidia-*包
6.2 构建镜像
docker build --ssh "default=$($env:USERPROFILE)\.ssh\id_ed25519" -f Dockerfile -t tianlu-api:latest .
6.3 验证优化效果
# 检查镜像大小
docker images tianlu-api:latest
# 验证 torch 版本
docker run --rm tianlu-api:latest python -c "import torch; print(f'torch={torch.__version__}, cuda_available={torch.cuda.is_available()}')"
# 检查是否有 NVIDIA 包
docker run --rm tianlu-api:latest pip list | grep -i nvidia
期望结果:
镜像体积在 3-5GB 范围内
cuda_available=False没有
nvidia-*包
7. 配置验证清单
[ ]
pyproject.toml中dependencies包含torch>=2.4.1[ ]
pyproject.toml中配置了pytorch-cpu索引(explicit = true)[ ]
pyproject.toml中[tool.uv.sources]指定了torch = { index = "pytorch-cpu" }[ ] 已执行
uv lock重新生成锁定文件[ ] Dockerfile 中使用
--no-dev参数[ ] Dockerfile 中在 runtime 阶段包含清理步骤(删除
__pycache__、测试文件、nvidia 目录等)[ ] 清理步骤在复制前执行(确保 COPY 层只包含清理后的文件)
[ ] 构建后验证镜像体积(期望 3-5GB)
[ ] 验证镜像中 torch 为 CPU 版本(
cuda_available=False)[ ] 验证镜像中不包含
nvidia-*依赖包
8. 常见问题
Q1: 本地开发环境也需要使用 CPU 版本的 torch 吗?
A: 配置后,本地环境也会使用 CPU 版本的 torch。如果需要在本地使用 CUDA 版本:
可以创建分支或使用不同的
uv.lock文件或者临时注释
[tool.uv.sources]中的 torch 配置
Q2: 如果 uv lock 报错怎么办?
A:
确保网络可以访问
https://download.pytorch.org/whl/cpu检查
pyproject.toml语法是否正确尝试删除
uv.lock后重新生成
Q3: 镜像体积仍然很大怎么办?
A:
参考第 4 章"镜像体积排查与诊断"进行详细排查
确认已执行清理步骤(删除
__pycache__、测试文件等)确认使用的是 CPU 版本的 PyTorch(最重要的优化)
使用
docker history和du -sh定位大文件
Q4: 运行时 uv 命令无法使用?
A:
确认
uv二进制文件已复制到/usr/local/bin/uv确认
appuser有权限访问/home/appuser/.cache/uv目录确认
PATH环境变量包含/usr/local/bin
Q5: 优化后镜像体积应该是多少?
A:
包含完整科学计算栈的镜像,3-5GB 是合理的范围
如果超过 5GB,建议按照第 4 章进行排查
如果小于 3GB,说明优化效果很好
9. 参考资料
最后更新: 2025-01-XX


