
haowallpaper单张图片原图爬取
📋 目录
背景模块
1.1 网站介绍
好壁纸 (haowallpaper.com) 是一个提供免费4K高清电脑壁纸、动态壁纸、素材图片、背景美图的网站。
主要功能: 提供壁纸下载服务(网站仅可以查看预览图,原图需要点击下载)
反爬机制: 使用 ALTCHA 验证系统防止自动化爬取
1.2 反爬机制分析
网站采用了 ALTCHA 验证系统,这是一种基于工作量证明(Proof of Work)的验证机制:
挑战-响应机制: 服务器生成一个哈希挑战,客户端需要找到匹配的数字
动态验证: 每次请求都需要重新获取挑战并解决
签名验证: 使用服务器签名确保挑战的有效性
1.3 爬虫目标
✅ 绕过 ALTCHA 验证系统
✅ 获取图片/视频的完整下载链接
✅ 批量下载壁纸资源
✅ 自动分类保存(图片/视频)
1.4 网站操作
进入网站找一个图片进入详情点击下载:
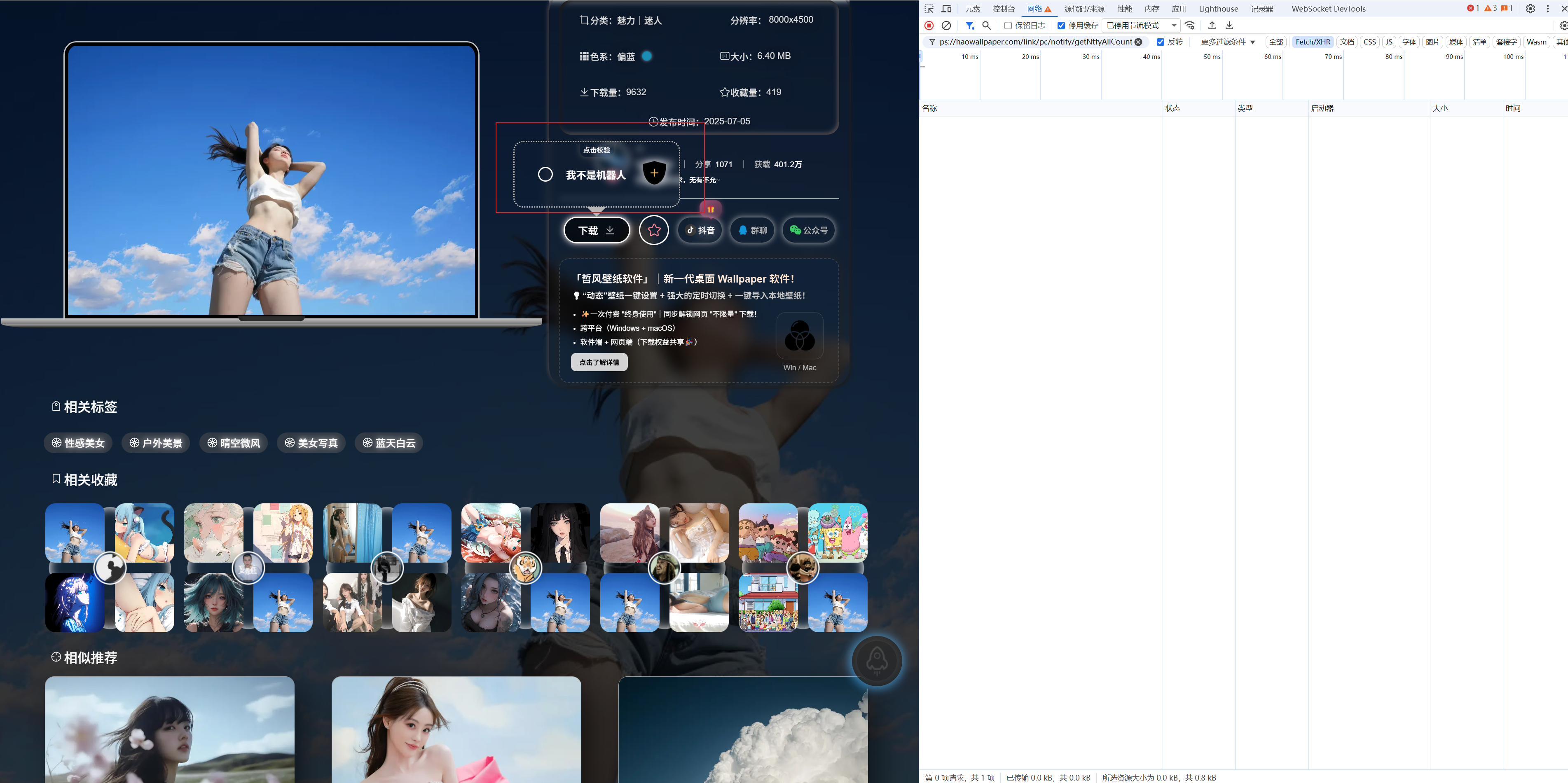
查看 https://haowallpaper.com/link/pc/certify/challenge 接口的返回值和 https://haowallpaper.com/link/pc/certify/verify接口的传参
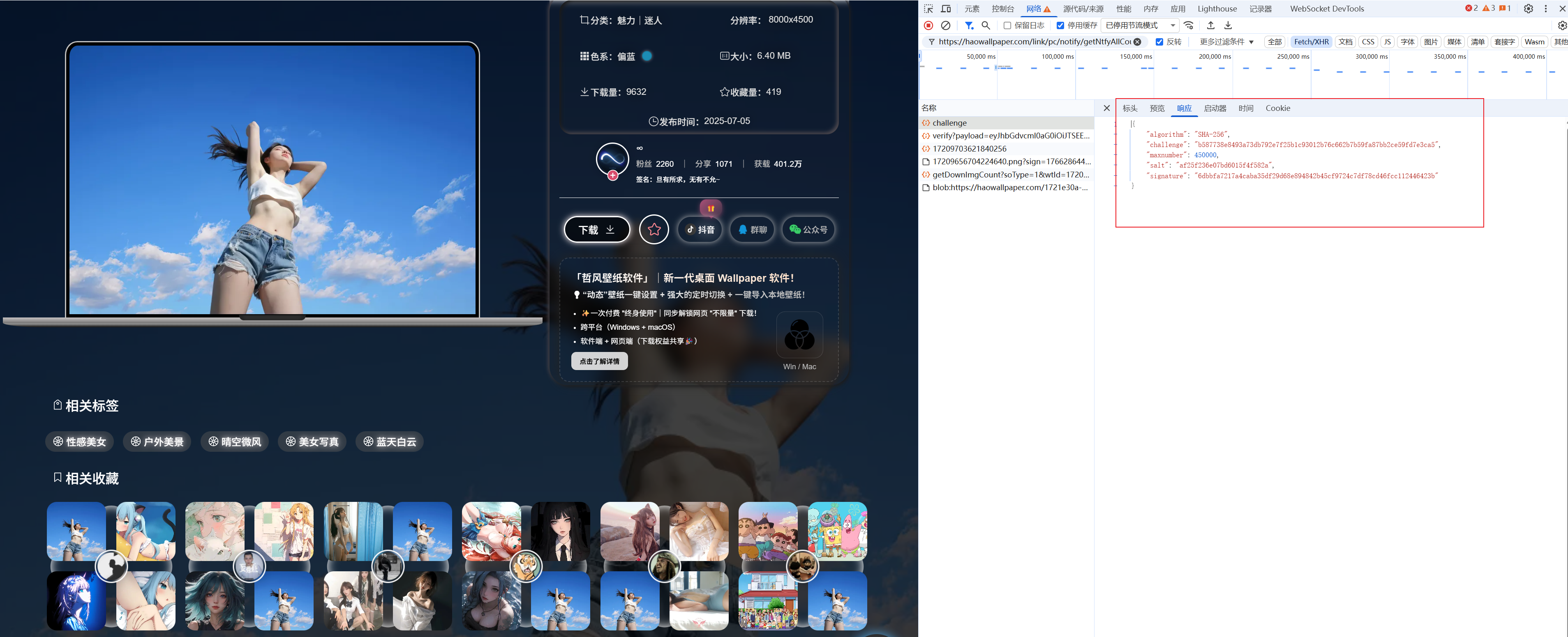
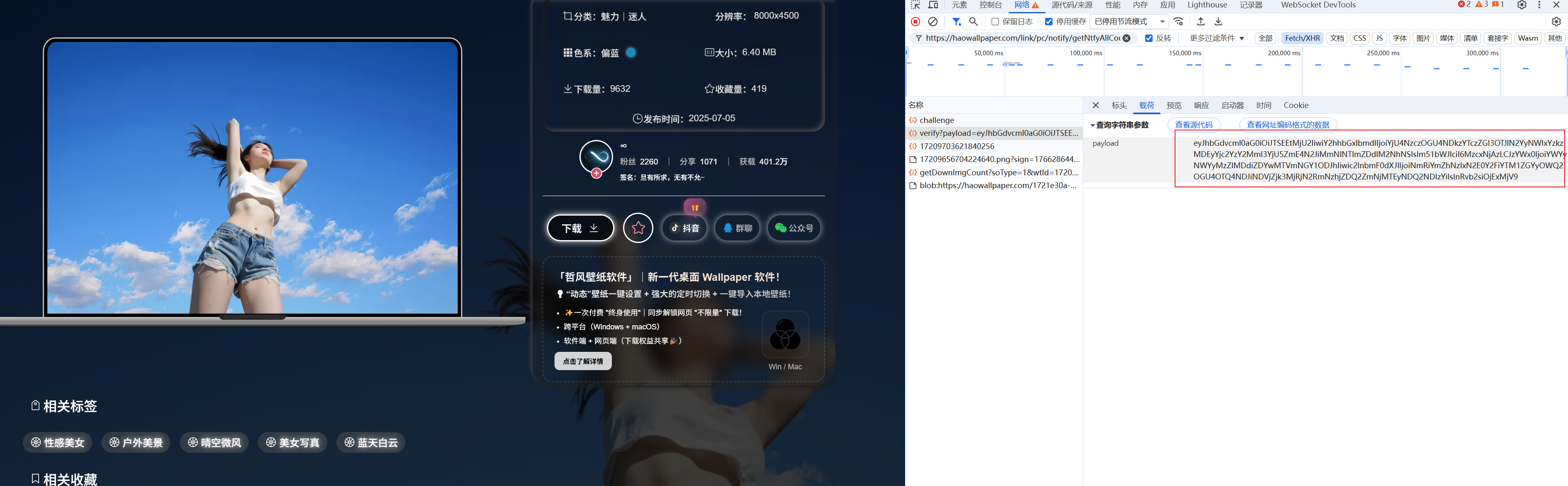
到这里已经知道是根据前面的返回值 做了一定的操作之后得到的这个pylaod,关于前端加密一般都是用到base64、hash、aes、des、rsa算法操作处理,所以一般直接点进去下图圈中的搜这类关键字能在js代码里找到加密逻辑
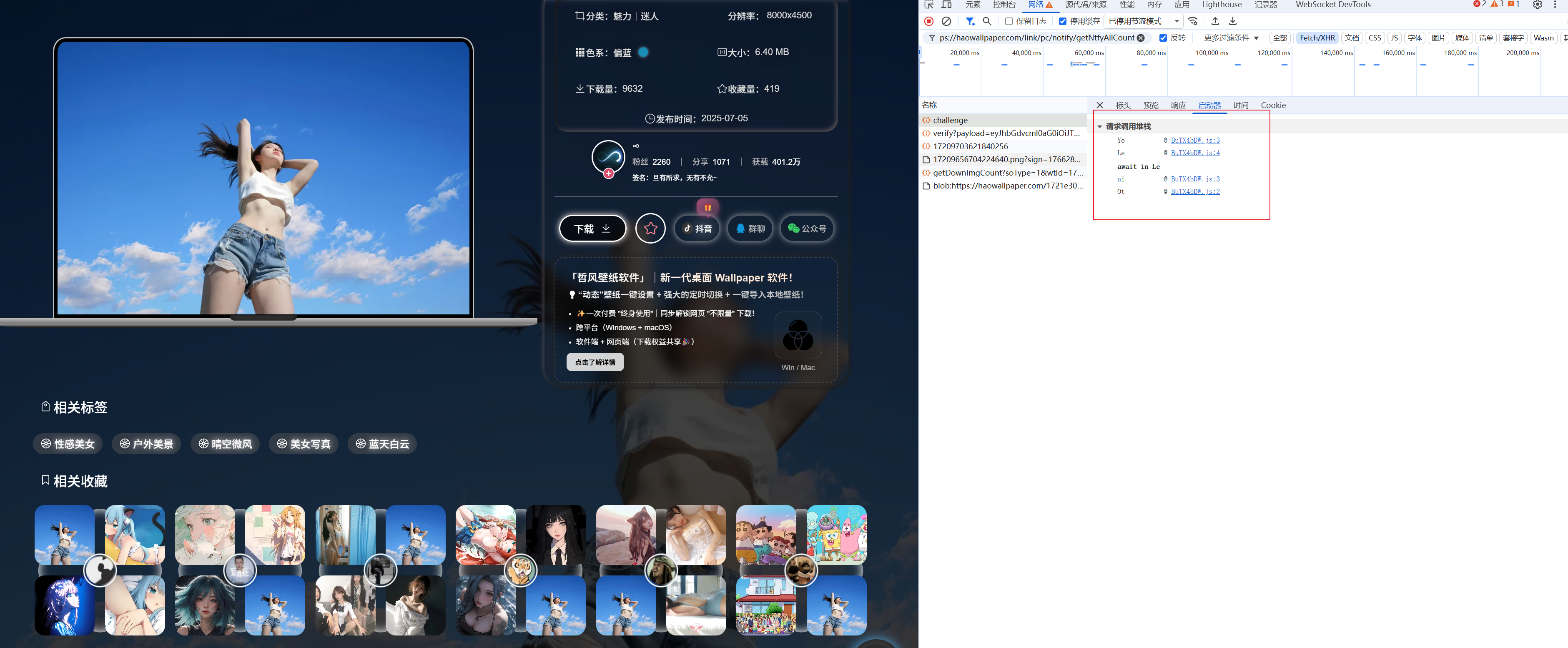
查看调用栈
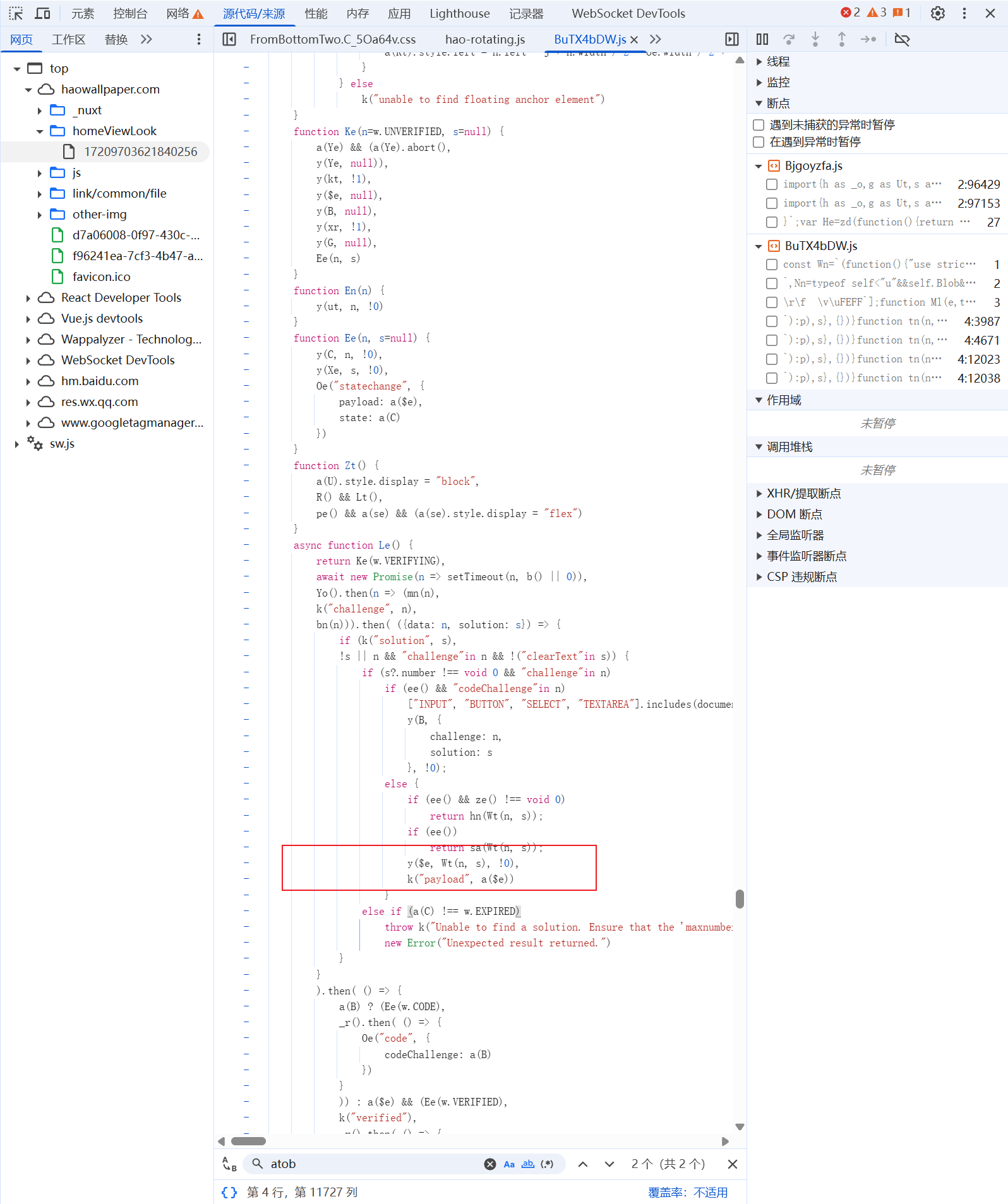
我们可以看到大概是在这里做的加密处理,但是传统的自己一个个打断点调试比较费时,所以这里我的处理是吧这个文件给到ai,输入prompt,让ai去梳理下这边的加密逻辑,可能几个小时的工作量,ai几十秒就处理好了
继续往下看https://haowallpaper.com/link/common/file/getCompleteUrl/17209703621840256 接口直接就能获取到图片下载地址了
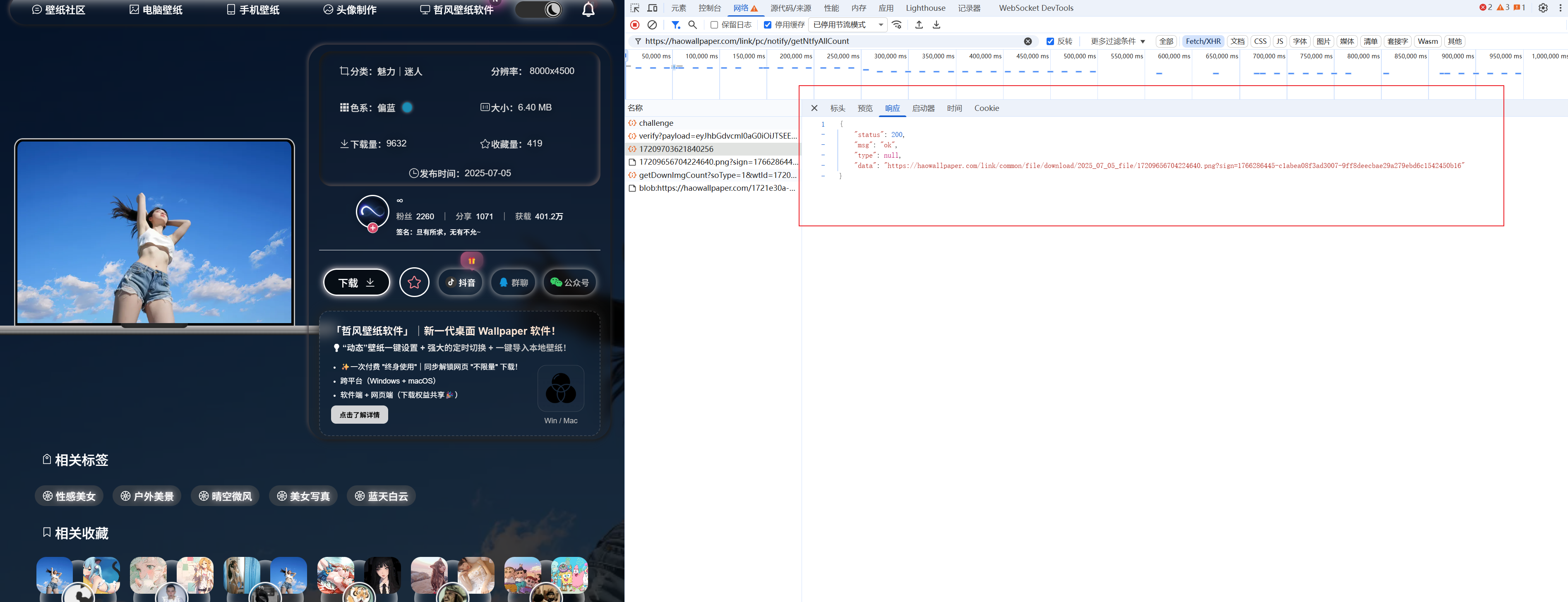
需要注意的是:
https://haowallpaper.com/link/pc/certify/verify和https://haowallpaper.com/link/common/file/getCompleteUrl/17209703621840256接口 必须在请求头带上tokenhttps://haowallpaper.com/link/pc/certify/verify接口有验证有效期,估计只有几秒,所以 验证通过后尽快去请求图片访问地址
整体功能流程模块
2.1 完整爬取流程
文本流程图
开始爬取
↓
┌─────────────────────────────────────┐
│ 1. 获取挑战数据 │
│ GET /link/pc/certify/challenge │
│ 返回: {algorithm, challenge, │
│ maxnumber, salt, signature} │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 2. 暴力破解挑战 │
│ 遍历数字 0 ~ maxnumber │
│ 计算: hash(salt + number) │
│ 找到匹配 challenge 的数字 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 3. 生成 Payload │
│ {algorithm, challenge, number, │
│ salt, signature, took} │
│ 编码为 Base64 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 4. 验证 Payload │
│ POST /link/pc/certify/verify │
│ 参数: payload (Base64) │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 5. 获取文件完整 URL │
│ GET /link/common/file/ │
│ getCompleteUrl/{file_id} │
│ 返回: {data: "下载链接"} │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 6. 下载文件 │
│ 从 URL 提取文件名 │
│ 保存到 images/ 或 videos/ │
└─────────────────────────────────────┘
↓
完成
Mermaid 流程图
flowchart TD
A[开始爬取] --> B[1. 获取挑战数据]
B --> C{获取成功?}
C -->|否| Z[失败]
C -->|是| D[2. 暴力破解挑战]
D --> E{找到匹配数字?}
E -->|否| Z
E -->|是| F[3. 生成 Payload]
F --> G[4. 验证 Payload]
G --> H{验证成功?}
H -->|否| Z
H -->|是| I[5. 获取文件完整 URL]
I --> J{获取成功?}
J -->|否| Z
J -->|是| K[6. 下载文件]
K --> L{文件类型?}
L -->|图片| M[保存到 images/]
L -->|视频| N[保存到 videos/]
M --> O[完成]
N --> O
2.2 核心接口说明
2.3 数据流转图
文本流程图
┌─────────────┐
│ 服务器 │
│ (API) │
└──────┬──────┘
│ 1. 挑战数据
↓
┌──────┴──────┐
│ 爬虫程序 │
│ │
│ ┌────────┐ │
│ │ 破解 │ │
│ │ 挑战 │ │
│ └────┬───┘ │
│ │ │
│ ┌────▼───┐ │
│ │ 生成 │ │
│ │Payload │ │
│ └────┬───┘ │
└───────┼─────┘
│ 2. Payload
↓
┌───────┴───────┐
│ 服务器验证 │
└───────┬───────┘
│ 3. 验证成功
↓
┌───────┴───────┐
│ 获取下载链接 │
└───────┬───────┘
│ 4. 文件URL
↓
┌───────┴───────┐
│ 下载文件 │
└───────────────┘
Mermaid 序列图
sequenceDiagram
participant C as 爬虫程序
participant S as 服务器
C->>S: GET /challenge
S-->>C: 挑战数据 {algorithm, challenge, salt, ...}
Note over C: 暴力破解挑战<br/>找到匹配的 number
C->>C: 生成 Payload
C->>C: Base64 编码
C->>S: POST /verify (payload)
S-->>C: 验证成功
C->>S: GET /getCompleteUrl/{file_id}
S-->>C: 下载链接 {data: "https://..."}
C->>S: GET 下载链接
S-->>C: 文件数据 (图片/视频)
Note over C: 保存到本地<br/>images/ 或 videos/
JS逆向模块
3.1 ALTCHA 验证原理
ALTCHA 是一种基于工作量证明的验证系统,其核心思想是:
服务器生成挑战: 随机生成 salt 和目标哈希值 challenge
客户端解决挑战: 通过暴力破解找到满足条件的 number
验证解决方案: 服务器验证 number 是否正确
3.2 挑战数据结构
{
"algorithm": "SHA-256", // 哈希算法
"challenge": "c64cddd0c0a058f...", // 目标哈希值(64字符)
"maxnumber": 450000, // 最大尝试数字
"salt": "94a19886c435e3786...", // 盐值(随机字符串)
"signature": "03c335e731a44..." // 服务器签名(用于验证)
}
3.3 挑战解决算法
// 伪代码
function solveChallenge(challenge, salt, algorithm, maxNumber) {
for (let number = 0; number <= maxNumber; number++) {
const input = salt + number;
const hash = calculateHash(input, algorithm);
if (hash === challenge) {
return {
number: number,
took: elapsedTime
};
}
}
return null; // 未找到
}
3.4 Payload 生成流程
文本流程图
挑战数据 (n)
↓
┌─────────────────────┐
│ 解决挑战 (bn) │
│ 找到 number │
└──────────┬──────────┘
│
↓
┌─────────────────────┐
│ 组合 Payload │
│ { │
│ algorithm, │
│ challenge, │
│ number, │
│ salt, │
│ signature, │
│ took │
│ } │
└──────────┬──────────┘
│
↓
┌─────────────────────┐
│ JSON.stringify() │
└──────────┬──────────┘
│
↓
┌─────────────────────┐
│ Base64 编码 (Wt) │
└──────────┬──────────┘
│
↓
Base64 Payload
Mermaid 流程图
flowchart LR
A[挑战数据] --> B[解决挑战]
B --> C[找到 number]
C --> D[组合 Payload]
D --> E[JSON.stringify]
E --> F[Base64 编码]
F --> G[Base64 Payload]
style A fill:#e1f5ff
style G fill:#c8e6c9
3.5 关键函数映射
3.6 哈希计算示例
function calculate_hash(salt, number, algorithm):
input_data = salt + number
switch algorithm:
case "SHA-256":
return sha256(input_data).hexdigest().to_lowercase()
case "MD5":
return md5(input_data).hexdigest().to_lowercase()
case "SHA-384":
return sha384(input_data).hexdigest().to_lowercase()
case "SHA-512":
return sha512(input_data).hexdigest().to_lowercase()
default:
throw "不支持的算法"
3.7 验证流程时序图
文本时序图
客户端 服务器
│ │
│── GET /challenge ──────>│
│<── 挑战数据 ────────────│
│ │
│ [暴力破解] │
│ │
│── POST /verify ────────>│
│ payload │
│<── 验证结果 ────────────│
│ │
│── GET /getCompleteUrl ─>│
│ file_id │
│<── 下载链接 ────────────│
│ │
│── GET 下载链接 ────────>│
│<── 文件数据 ────────────│
│ │
Mermaid 时序图
sequenceDiagram
participant Client as 客户端/爬虫
participant Server as 服务器
Client->>Server: GET /link/pc/certify/challenge
Server-->>Client: {algorithm, challenge, salt, maxnumber, signature}
Note over Client: 暴力破解挑战<br/>计算 hash(salt + number)
Client->>Client: 找到匹配的 number
Client->>Client: 生成 Payload
Client->>Client: Base64 编码
Client->>Server: POST /link/pc/certify/verify<br/>payload: Base64字符串
Server-->>Client: 验证成功
Client->>Server: GET /link/common/file/getCompleteUrl/{file_id}<br/>Header: token
Server-->>Client: {status: 200, data: "下载链接"}
Client->>Server: GET 下载链接
Server-->>Client: 文件数据 (二进制)
Note over Client: 保存文件<br/>images/ 或 videos/
代码实现模块
4.1 实现思路
爬虫的核心实现思路分为以下几个模块:
挑战获取模块: 从服务器获取 ALTCHA 挑战数据
挑战破解模块: 通过暴力破解找到匹配的数字
验证模块: 将破解结果编码后发送到服务器验证
文件获取模块: 获取文件的完整下载链接
下载模块: 下载文件并自动分类保存
4.2 关键算法伪代码
4.2.1 挑战破解算法
function brute_force_challenge(challenge, salt, algorithm, max_number):
start_time = current_time()
for number from 0 to max_number:
input = salt + number
hash = calculate_hash(input, algorithm)
if hash == challenge:
took = (current_time() - start_time) * 1000
return {number: number, took: took}
return null // 未找到匹配
4.2.2 Payload 生成算法
function generate_payload(challenge_data):
// 1. 破解挑战
solution = brute_force_challenge(
challenge_data.challenge,
challenge_data.salt,
challenge_data.algorithm,
challenge_data.maxnumber
)
// 2. 组合 Payload
payload = {
algorithm: challenge_data.algorithm,
challenge: challenge_data.challenge,
number: solution.number,
salt: challenge_data.salt,
signature: challenge_data.signature,
took: solution.took
}
// 3. 编码为 Base64
json_string = JSON.stringify(payload)
base64_payload = base64_encode(json_string)
return base64_payload
4.2.3 文件名提取算法
function extract_filename_from_url(url):
// 使用正则表达式匹配: 数字.扩展名
pattern = "(\d+\.(png|jpg|jpeg|gif|webp|bmp|mp4|mov|avi|webm|mkv))"
match = regex_search(url, pattern, case_insensitive)
if match:
return match.group(1)
else:
return generate_default_filename()
4.2.4 文件分类算法
function classify_file(filename):
video_extensions = [".mp4", ".mov", ".avi", ".webm", ".mkv"]
extension = get_extension(filename).to_lowercase()
if extension in video_extensions:
return "videos"
else:
return "images"
4.3 完整代码流程图
文本流程图
开始
↓
crawl_single_file(file_id)
↓
┌─────────────────────────┐
│ generate_challenge_ │
│ payload() │
│ ↓ │
│ fetch_challenge() │
│ ↓ │
│ generate_payload() │
│ ↓ │
│ brute_force_challenge() │
│ ↓ │
│ encode_payload() │
└──────────┬──────────────┘
↓
┌─────────────────────────┐
│ verify_payload() │
└──────────┬──────────────┘
↓
┌─────────────────────────┐
│ get_complete_url() │
└──────────┬──────────────┘
↓
┌─────────────────────────┐
│ extract_and_download_ │
│ image() │
│ ↓ │
│ extract_filename_from_ │
│ url() │
│ ↓ │
│ download_image() │
└──────────┬──────────────┘
↓
返回路径
↓
结束
Mermaid 函数调用流程图
flowchart TD
Start([开始]) --> A[crawl_single_file]
A --> B[generate_challenge_payload]
B --> C[fetch_challenge]
C --> D[generate_payload]
D --> E[brute_force_challenge]
E --> F[encode_payload]
F --> G[verify_payload]
G --> H[get_complete_url]
H --> I[extract_and_download_image]
I --> J[extract_filename_from_url]
J --> K[download_image]
K --> L[返回保存路径]
L --> End([结束])
style Start fill:#c8e6c9
style End fill:#c8e6c9
style E fill:#fff9c4
style K fill:#e1f5ff
📝 总结
关键技术点
ALTCHA 验证绕过: 通过暴力破解找到匹配的数字
哈希算法支持: SHA-256, MD5, SHA-384, SHA-512
自动文件分类: 根据扩展名自动分类保存
正则提取文件名: 从 URL 中提取文件名
注意事项
⚠️ 遵守网站使用条款: 不要过度频繁请求
⚠️ 验证有效期:
/link/pc/certify/verify接口验证成功的有效期很短,验证成功后必须立即调用/link/common/file/getCompleteUrl/{file_id}接口获取文件下载地址,否则验证会失效⚠️ Token 格式和下载次数:
访客模式:Token 格式为
ack:_176624447295218604760541523,下载次数有限微信登录:每天有 10 次免费下载次数
付费会员:29 元可购买永久无限下载权限
需要定期更新 token(特别是访客模式的 token 可能有时效性)
Token 有效期未确认:当前不清楚 token 是否有过期时间,需要自行注意 token 的有效性
⚠️ 访问频率限制:
不清楚网站是否有访问频率限制
建议不要并行爬取,避免触发频率限制
不确定并行爬取是否会影响
/link/pc/certify/verify接口的验证效果建议采用串行爬取,在每次请求之间适当添加延迟
⚠️ 文件大小: 视频文件可能很大,注意磁盘空间
⚠️ 网络超时: 大文件下载需要设置合理的超时时间
扩展功能
[ ] 批量爬取列表页面的所有文件
[ ] 添加进度条显示
[ ] 添加日志记录功能
附录:代码实现详解
A.1 项目结构
violet-wallpaper-backend/
├── src/
│ └── utils/
│ ├── crawl_util.py # ALTCHA 验证工具
│ └── image_crawler.py # 图片爬虫主程序
├── images/ # 图片保存目录
└── videos/ # 视频保存目录
A.2 核心函数说明
A.2.1 crawl_util.py - ALTCHA 验证工具
主要函数:
brute_force_challenge()- 暴力破解挑战def brute_force_challenge( challenge: str, salt: str, algorithm: str, max_number: int, show_progress: bool = True ) -> Optional[Dict[str, Any]]功能: 遍历数字找到匹配 challenge 的 number
返回:
{number: int, took: int}或None
generate_payload()- 生成 Payloaddef generate_payload(challenge_data: Dict[str, Any]) -> Dict[str, Any]功能: 根据挑战数据生成完整的 payload
返回: Payload 字典
encode_payload()- 编码 Payloaddef encode_payload(payload: Dict[str, Any]) -> str功能: 将 payload 编码为 Base64 字符串
返回: Base64 编码的字符串
A.2.2 image_crawler.py - 爬虫主程序
主要函数:
fetch_challenge()- 获取挑战数据def fetch_challenge(url: str = CHALLENGE_URL) -> Dict[str, Any]功能: 从服务器获取 ALTCHA 挑战数据
generate_challenge_payload()- 生成挑战 Payloaddef generate_challenge_payload( url: str = CHALLENGE_URL, silent: bool = False ) -> Dict[str, Any]功能: 完整的挑战解决流程
verify_payload()- 验证 Payloaddef verify_payload( payload_base64: str, verify_url: str = VERIFY_URL, silent: bool = False ) -> Dict[str, Any]功能: 将 payload 发送到服务器验证
get_complete_url()- 获取完整下载链接def get_complete_url( file_id: str, base_url: str = COMPLETE_URL_BASE, silent: bool = False ) -> Dict[str, Any]功能: 根据文件 ID 获取下载链接
download_image()- 下载文件def download_image( image_url: str, save_path: Optional[str] = None, silent: bool = False ) -> str功能: 下载图片或视频并保存到本地
crawl_single_file()- 爬取单个文件(主入口)def crawl_single_file( file_id: str, silent: bool = False ) -> str功能: 完整的爬取流程封装
流程: 获取挑战 → 破解 → 验证 → 获取链接 → 下载
A.3 使用示例
A.3.1 爬取单个文件
from src.utils.image_crawler import crawl_single_file
# 爬取单个文件
file_id = "16812449365937536"
saved_path = crawl_single_file(file_id)
print(f"文件已保存到: {saved_path}")
A.3.2 批量爬取
from src.utils.image_crawler import crawl_single_file
file_ids = [
"16812449365937536",
"17805363362909568",
"17805358249069952"
]
for file_id in file_ids:
try:
saved_path = crawl_single_file(file_id, silent=True)
print(f"✅ {file_id}: {saved_path}")
except Exception as e:
print(f"❌ {file_id}: {e}")
A.3.3 自定义保存路径
from src.utils.image_crawler import (
get_complete_url,
extract_and_download_image
)
# 获取下载链接
complete_url_result = get_complete_url("16812449365937536")
# 自定义保存路径
saved_path = extract_and_download_image(
complete_url_result,
save_path="custom_folder/my_image.png"
)
A.4 文件分类逻辑
def is_video_file(filename: str) -> bool:
"""判断文件是否为视频"""
video_extensions = {'.mp4', '.mov', '.avi', '.webm', '.mkv'}
return Path(filename).suffix.lower() in video_extensions
# 自动分类保存
if is_video_file(filename):
save_dir = Path("videos")
else:
save_dir = Path("images")
A.5 文件名提取逻辑
import re
def extract_filename_from_url(url: str) -> Optional[str]:
"""使用正则表达式从 URL 中提取文件名"""
# 匹配格式: 数字.扩展名
pattern = r'(\d+\.(?:png|jpg|jpeg|gif|webp|bmp|mp4|mov|avi|webm|mkv))'
match = re.search(pattern, url, re.IGNORECASE)
return match.group(1) if match else None
A.6 错误处理
try:
saved_path = crawl_single_file(file_id)
except requests.RequestException as e:
print(f"网络请求失败: {e}")
except ValueError as e:
print(f"数据格式错误: {e}")
except Exception as e:
print(f"未知错误: {e}")
A.7 性能优化建议
并行破解: 使用多线程/多进程并行破解挑战
缓存挑战: 相同 salt 的挑战可以缓存结果
断点续传: 下载大文件时支持断点续传
请求重试: 网络错误时自动重试
📝 总结
关键技术点
ALTCHA 验证绕过: 通过暴力破解找到匹配的数字
哈希算法支持: SHA-256, MD5, SHA-384, SHA-512
自动文件分类: 根据扩展名自动分类保存
正则提取文件名: 从 URL 中提取文件名
注意事项
⚠️ 遵守网站使用条款: 不要过度频繁请求
⚠️ 验证有效期:
/link/pc/certify/verify接口验证成功的有效期很短,验证成功后必须立即调用/link/common/file/getCompleteUrl/{file_id}接口获取文件下载地址,否则验证会失效⚠️ Token 格式和下载次数:
访客模式:Token 格式为
ack:_176624447295218604760541523,下载次数有限微信登录:每天有 10 次免费下载次数
付费会员:29 元可购买永久无限下载权限
需要定期更新 token(特别是访客模式的 token 可能有时效性)
Token 有效期未确认:当前不清楚 token 是否有过期时间,需要自行注意 token 的有效性
⚠️ 访问频率限制:
不清楚网站是否有访问频率限制
建议不要并行爬取,避免触发频率限制
不确定并行爬取是否会影响
/link/pc/certify/verify接口的验证效果建议采用串行爬取,在每次请求之间适当添加延迟
⚠️ 文件大小: 视频文件可能很大,注意磁盘空间
⚠️ 网络超时: 大文件下载需要设置合理的超时时间
扩展功能
[ ] 批量爬取列表页面的所有文件
[ ] 支持断点续传
[ ] 添加进度条显示
[ ] 支持代理配置
[ ] 添加日志记录功能
🔗 相关资源
完整代码实现
B.1 src/utils/crawl_util.py - ALTCHA 验证工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ALTCHA 验证生成工具
根据输入的挑战数据(algorithm, challenge, maxnumber, salt, signature),
通过暴力破解找到匹配的 number,然后生成对应算法版本的 payload
"""
import base64
import json
import hashlib
import sys
import io
import time
from typing import Dict, Optional, Any
# 设置标准输出编码为 UTF-8(Windows 兼容)
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8', errors='replace')
def generate_md5_challenge(salt: str, number: int) -> str:
"""
生成 MD5 挑战哈希值
Args:
salt: 盐值
number: 数字
Returns:
MD5 哈希值(十六进制)
"""
input_data = salt + str(number)
return hashlib.md5(input_data.encode('utf-8')).hexdigest().lower()
def brute_force_challenge(
challenge: str,
salt: str,
algorithm: str,
max_number: int,
show_progress: bool = True
) -> Optional[Dict[str, Any]]:
"""
暴力破解挑战,找到匹配的 number
Args:
challenge: 目标哈希值
salt: 盐值
algorithm: 哈希算法 (SHA-256, MD5 等)
max_number: 最大尝试数字
show_progress: 是否显示进度
Returns:
如果找到匹配,返回包含 number 和 took 的字典,否则返回 None
"""
start_time = time.time()
algorithm_upper = algorithm.upper().replace('-', '')
hash_functions = {
'SHA256': hashlib.sha256,
'SHA384': hashlib.sha384,
'SHA512': hashlib.sha512,
'MD5': hashlib.md5,
}
if algorithm_upper not in hash_functions:
raise ValueError(f"不支持的哈希算法: {algorithm}")
hash_func = hash_functions[algorithm_upper]
for number in range(max_number + 1):
input_data = salt + str(number)
calculated_hash = hash_func(input_data.encode('utf-8')).hexdigest().lower()
if calculated_hash == challenge.lower():
took = int((time.time() - start_time) * 1000) # 转换为毫秒
return {
'number': number,
'took': took
}
# 每 10000 次显示进度
if show_progress and number > 0 and number % 10000 == 0:
elapsed = time.time() - start_time
rate = number / elapsed if elapsed > 0 else 0
progress = number * 100 // max_number if max_number > 0 else 0
print(f"进度: {number}/{max_number} ({progress}%) - "
f"速度: {rate:.0f} 次/秒", end='\r', flush=True)
# 如果未找到匹配,清除进度行并换行
if show_progress:
print() # 换行
return None
def calculate_hash(data: str, algorithm: str) -> str:
"""
计算字符串的哈希值
Args:
data: 要哈希的数据
algorithm: 哈希算法名称 (SHA-256, SHA-384, SHA-512, MD5)
Returns:
十六进制格式的哈希值
"""
algorithm = algorithm.upper().replace('-', '')
hash_functions = {
'SHA256': hashlib.sha256,
'SHA384': hashlib.sha384,
'SHA512': hashlib.sha512,
'MD5': hashlib.md5,
}
if algorithm not in hash_functions:
raise ValueError(f"不支持的哈希算法: {algorithm}")
hash_func = hash_functions[algorithm]
return hash_func(data.encode('utf-8')).hexdigest()
def generate_payload(challenge_data: Dict[str, Any]) -> Dict[str, Any]:
"""
根据输入的挑战数据生成对应算法版本的 payload
输入格式:
{
"algorithm": "SHA-256",
"challenge": "...",
"maxnumber": 450000,
"salt": "...",
"signature": "..."
}
输出格式:
{
"algorithm": "SHA-256", # 与输入相同
"challenge": "...", # 与输入相同(验证用)
"number": 123456, # 找到的数字
"salt": "...", # 与输入相同
"signature": "...", # 与输入相同
"took": 123 # 耗时(毫秒)
}
Args:
challenge_data: 输入的挑战数据
Returns:
对应算法版本的 payload 字典(使用输入的 algorithm)
Raises:
ValueError: 输入数据缺少必需字段或验证失败
KeyError: 输入数据格式错误
"""
# 验证必需字段
required_fields = ['algorithm', 'challenge', 'maxnumber', 'salt']
missing_fields = [field for field in required_fields if field not in challenge_data]
if missing_fields:
raise ValueError(f"输入数据缺少必需字段: {missing_fields}")
algorithm = challenge_data['algorithm']
challenge = challenge_data['challenge']
max_number = challenge_data['maxnumber']
salt = challenge_data['salt']
signature = challenge_data.get('signature', '')
# 验证字段类型
if not isinstance(algorithm, str):
raise ValueError(f"algorithm 必须是字符串,当前类型: {type(algorithm)}")
if not isinstance(challenge, str):
raise ValueError(f"challenge 必须是字符串,当前类型: {type(challenge)}")
if not isinstance(max_number, int) or max_number < 0:
raise ValueError(f"maxnumber 必须是非负整数,当前值: {max_number}")
if not isinstance(salt, str):
raise ValueError(f"salt 必须是字符串,当前类型: {type(salt)}")
# 第一步:暴力破解找到匹配的 number
print(f"正在破解挑战...")
print(f"算法: {algorithm}")
print(f"挑战: {challenge}")
print(f"盐值: {salt}")
print(f"最大数字: {max_number}")
solution = brute_force_challenge(challenge, salt, algorithm, max_number)
if not solution:
raise ValueError(f"未能在 {max_number} 次尝试内找到匹配的数字")
number = solution['number']
took = solution['took']
print(f"\n[成功] 找到匹配!")
print(f"数字: {number}")
print(f"耗时: {took}ms")
# 第二步:验证找到的 number 是否正确(使用相同的 algorithm)
print(f"\n验证挑战...")
input_data = salt + str(number)
calculated_hash = calculate_hash(input_data, algorithm).lower()
print(f"计算: {algorithm}(\"{salt}\" + {number})")
print(f"结果: {calculated_hash}")
print(f"目标: {challenge}")
if calculated_hash != challenge.lower():
raise ValueError(f"验证失败:计算的哈希值与挑战不匹配")
print(f"验证: [成功]")
# 创建 payload(使用输入的 algorithm,而不是强制转换为 MD5)
payload = {
"algorithm": algorithm,
"challenge": challenge, # 使用原始的 challenge
"number": number,
"salt": salt,
"signature": signature,
"took": took
}
return payload
def generate_md5_payload(challenge_data: Dict[str, Any]) -> Dict[str, Any]:
"""
根据输入的挑战数据生成 MD5 版本的 payload(兼容旧接口)
注意:此函数会先找到 number,然后生成 MD5 版本的 challenge
如果希望保持原始算法,请使用 generate_payload()
Args:
challenge_data: 输入的挑战数据
Returns:
MD5 版本的 payload 字典
"""
algorithm = challenge_data['algorithm']
challenge = challenge_data['challenge']
max_number = challenge_data['maxnumber']
salt = challenge_data['salt']
signature = challenge_data.get('signature', '')
# 第一步:暴力破解找到匹配的 number
print(f"正在破解挑战...")
print(f"算法: {algorithm}")
print(f"挑战: {challenge}")
print(f"盐值: {salt}")
print(f"最大数字: {max_number}")
solution = brute_force_challenge(challenge, salt, algorithm, max_number)
if not solution:
raise ValueError(f"未能在 {max_number} 次尝试内找到匹配的数字")
number = solution['number']
took = solution['took']
print(f"\n[成功] 找到匹配!")
print(f"数字: {number}")
print(f"耗时: {took}ms")
# 第二步:使用找到的 number 和 salt 生成 MD5 挑战
print(f"\n生成 MD5 挑战...")
md5_challenge = generate_md5_challenge(salt, number)
print(f"计算: MD5(\"{salt}\" + {number})")
print(f"MD5 挑战: {md5_challenge}")
# 创建 MD5 版本的 payload
md5_payload = {
"algorithm": "MD5",
"challenge": md5_challenge,
"number": number,
"salt": salt,
"signature": signature,
"took": took
}
return md5_payload
def encode_payload(payload: Dict[str, Any]) -> str:
"""
将 payload 字典编码为 Base64 字符串(类似 JavaScript 中的 Wt 函数)
Args:
payload: payload 字典
Returns:
Base64 编码的 payload 字符串
"""
json_string = json.dumps(payload, separators=(',', ':'))
base64_string = base64.b64encode(json_string.encode('utf-8')).decode('utf-8')
return base64_string
def main():
"""主函数 - 示例用法"""
# 示例输入数据
example_input = {
"algorithm": "SHA-256",
"challenge": "421cabbe541a7d4ff3a17ea752d2593a44c7a56c67fe1ad17c829e56b04c1668",
"maxnumber": 450000,
"salt": "27847bbe9608e6968849a511",
"signature": "167ebce7c12b17b39bd22c1531dcadaf635affedfb7ca65c6b2c30a029e89223"
}
print("=== ALTCHA 验证生成工具 ===\n")
print("输入数据:")
print(json.dumps(example_input, indent=2, ensure_ascii=False))
print()
try:
# 生成 payload(使用输入的 algorithm)
payload = generate_payload(example_input)
# 显示结果
print("\n生成的 Payload:")
print(json.dumps(payload, indent=2, ensure_ascii=False))
# 编码为 Base64
print("\nBase64 编码的 Payload:")
payload_base64 = encode_payload(payload)
print(payload_base64)
# 验证:解码并检查
print("\n验证 Base64 编码:")
decoded = json.loads(base64.b64decode(payload_base64).decode('utf-8'))
print(f"解码成功,algorithm: {decoded['algorithm']}, number: {decoded['number']}")
except Exception as e:
print(f"\n错误: {e}", file=sys.stderr)
import traceback
traceback.print_exc()
sys.exit(1)
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
print("\n\n用户中断")
sys.exit(1)
except Exception as error:
print(f"\n错误: {error}", file=sys.stderr)
import traceback
traceback.print_exc()
sys.exit(1)
B.2 src/utils/image_crawler.py - 图片爬虫主程序
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
图片爬虫工具
请求挑战接口获取挑战数据,生成 payload,并可选择性地请求验证接口
"""
import json
import sys
import time
import re
from pathlib import Path
import requests
import io
from typing import Dict, Any, Optional
# 添加项目根目录到 Python 路径
project_root = Path(__file__).parent.parent.parent
sys.path.insert(0, str(project_root))
from src.utils.crawl_util import generate_payload, encode_payload
CHALLENGE_URL = "https://haowallpaper.com/link/pc/certify/challenge"
VERIFY_URL = "https://haowallpaper.com/link/pc/certify/verify"
REFERER_URL = "https://haowallpaper.com/homeViewLook"
COMPLETE_URL_BASE = "https://haowallpaper.com/link/common/file/getCompleteUrl"
def fetch_challenge(url: str = CHALLENGE_URL) -> Dict[str, Any]:
"""
请求挑战接口获取挑战数据
Args:
url: 挑战接口 URL
Returns:
挑战数据字典,包含 algorithm, challenge, maxnumber, salt, signature
Raises:
requests.RequestException: 网络请求失败
ValueError: 响应数据格式错误
"""
try:
# 发送请求
response = requests.get(
url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'application/json',
},
timeout=10
)
# 检查 HTTP 状态码
response.raise_for_status()
# 解析 JSON
challenge_data = response.json()
# 验证必需字段
required_fields = ['algorithm', 'challenge', 'maxnumber', 'salt']
missing_fields = [field for field in required_fields if field not in challenge_data]
if missing_fields:
raise ValueError(f"响应数据缺少必需字段: {missing_fields}")
return challenge_data
except requests.RequestException as e:
raise requests.RequestException(f"请求挑战接口失败: {e}") from e
except json.JSONDecodeError as e:
raise ValueError(f"响应数据不是有效的 JSON: {e}") from e
def generate_challenge_payload(url: str = CHALLENGE_URL, silent: bool = False) -> Dict[str, Any]:
"""
获取挑战数据并生成 payload
Args:
url: 挑战接口 URL,默认使用 CHALLENGE_URL
silent: 是否静默模式(不打印进度信息)
Returns:
生成的 payload 字典
Raises:
requests.RequestException: 网络请求失败
ValueError: 数据格式错误或破解失败
"""
challenge_url = url
if not silent:
print(f"正在请求挑战接口: {challenge_url}")
# 获取挑战数据
challenge_data = fetch_challenge(challenge_url)
if not silent:
print("获取到的挑战数据:")
print(json.dumps(challenge_data, indent=2, ensure_ascii=False))
print()
# 生成 payload
# 如果 silent=True,临时重定向 stdout 以隐藏进度信息
if silent:
# 保存原始 stdout
original_stdout = sys.stdout
# 创建临时 stdout
temp_stdout = io.StringIO()
try:
# 重定向 stdout
sys.stdout = temp_stdout
# 生成 payload
payload = generate_payload(challenge_data)
finally:
# 恢复 stdout
sys.stdout = original_stdout
else:
payload = generate_payload(challenge_data)
return payload
def verify_payload(
payload_base64: str,
verify_url: str = VERIFY_URL,
silent: bool = False
) -> Dict[str, Any]:
"""
使用 payload 请求验证接口
Args:
payload: 生成的 payload 字典
verify_url: 验证接口 URL,默认使用 VERIFY_URL
silent: 是否静默模式(不打印详细信息)
Returns:
验证接口返回的响应数据
Raises:
requests.RequestException: 网络请求失败
ValueError: 响应数据格式错误或验证失败
"""
if not silent:
print(f"\n正在请求验证接口: {verify_url}")
print(f"Payload (Base64): {payload_base64[:50]}...") # 只显示前50个字符
try:
# 发送 POST 请求,payload 作为 JSON body
# 注意:根据实际 API 可能需要调整参数格式
request_data = {
'payload': payload_base64,
}
if not silent:
print(f"请求数据: {json.dumps(request_data, indent=2)}")
response = requests.post(
verify_url,
params=request_data,
headers={
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
# 'Accept': 'application/json',
# 'Content-Type': 'application/json',
# 'Referer': REFERER_URL,
},
timeout=30 # 增加超时时间
)
if not silent:
print(f"响应状态码: {response.status_code}")
# 检查 HTTP 状态码
response.raise_for_status()
# 解析 JSON 响应
try:
result = response.json()
except json.JSONDecodeError:
# 如果不是 JSON,返回文本内容
result = {'status_code': response.status_code, 'text': response.text}
if not silent:
print(f"\n验证接口响应:")
print(json.dumps(result, indent=2, ensure_ascii=False))
return result
except requests.Timeout:
error_msg = f"请求验证接口超时(超过30秒)"
raise requests.RequestException(error_msg)
except requests.RequestException as e:
error_msg = f"请求验证接口失败: {e}"
if hasattr(e, 'response') and e.response is not None:
try:
error_detail = e.response.json()
error_msg += f"\n响应详情: {json.dumps(error_detail, indent=2, ensure_ascii=False)}"
except:
error_msg += f"\n响应状态码: {e.response.status_code}\n响应内容: {e.response.text[:500]}"
else:
error_msg += f"\n请求URL: {verify_url}"
error_msg += f"\nPayload长度: {len(payload_base64)}"
raise requests.RequestException(error_msg) from e
def get_complete_url(
file_id: str,
base_url: str = COMPLETE_URL_BASE,
silent: bool = False
) -> Dict[str, Any]:
"""
获取文件的完整 URL
Args:
file_id: 文件 ID(如 16812449365937536)
base_url: 基础 URL,默认使用 COMPLETE_URL_BASE
silent: 是否静默模式(不打印详细信息)
Returns:
接口返回的响应数据
Raises:
requests.RequestException: 网络请求失败
ValueError: 响应数据格式错误
"""
url = f"{base_url}/{file_id}"
if not silent:
print(f"\n正在请求完整 URL: {url}")
try:
response = requests.get(
url,
headers={
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
# 'Accept': 'application/json',
# 'Referer': REFERER_URL,
# 当前token为我自己的微信登录后获取的token
'token': 'xxxx',
},
timeout=30
)
if not silent:
print(f"响应状态码: {response.status_code}")
# 检查 HTTP 状态码
response.raise_for_status()
# 解析 JSON 响应
try:
result = response.json()
except json.JSONDecodeError:
# 如果不是 JSON,返回文本内容
result = {'status_code': response.status_code, 'text': response.text}
if not silent:
print(f"\n完整 URL 响应:")
print(json.dumps(result, indent=2, ensure_ascii=False))
return result
except requests.Timeout:
error_msg = f"请求完整 URL 超时(超过30秒)"
raise requests.RequestException(error_msg)
except requests.RequestException as e:
error_msg = f"请求完整 URL 失败: {e}"
if hasattr(e, 'response') and e.response is not None:
try:
error_detail = e.response.json()
error_msg += f"\n响应详情: {json.dumps(error_detail, indent=2, ensure_ascii=False)}"
except:
error_msg += f"\n响应状态码: {e.response.status_code}\n响应内容: {e.response.text[:500]}"
else:
error_msg += f"\n请求URL: {url}"
raise requests.RequestException(error_msg) from e
def extract_filename_from_url(url: str) -> Optional[str]:
"""
使用正则表达式从 URL 中提取文件名(格式:数字.扩展名)
Args:
url: 文件 URL
Returns:
提取的文件名,如果未找到则返回 None
"""
# 匹配格式:数字.扩展名(如 16812418908081536.png)
# 支持的扩展名:图片(png, jpg, jpeg, gif, webp, bmp)和视频(mp4, mov, avi, webm, mkv)
pattern = r'(\d+\.(?:png|jpg|jpeg|gif|webp|bmp|mp4|mov|avi|webm|mkv))'
match = re.search(pattern, url, re.IGNORECASE)
if match:
return match.group(1)
return None
def is_video_file(filename: str) -> bool:
"""
判断文件是否为视频文件
Args:
filename: 文件名
Returns:
如果是视频文件返回 True,否则返回 False
"""
video_extensions = {'.mp4', '.mov', '.avi', '.webm', '.mkv'}
ext = Path(filename).suffix.lower()
return ext in video_extensions
def download_image(
image_url: str,
save_path: Optional[str] = None,
silent: bool = False
) -> str:
"""
下载图片或视频并保存到本地
Args:
image_url: 文件 URL(可能是图片或视频)
save_path: 保存路径(可选,如果不提供则从 URL 中提取文件名)
silent: 是否静默模式(不打印详细信息)
Returns:
保存的文件路径
Raises:
requests.RequestException: 网络请求失败
ValueError: URL 无效或保存路径无效
"""
if not silent:
print(f"\n正在下载文件: {image_url}")
try:
# 发送 GET 请求下载文件
response = requests.get(
image_url,
headers={
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
},
timeout=120, # 视频下载可能需要更长时间
stream=True # 流式下载,避免内存占用过大
)
# 检查 HTTP 状态码
response.raise_for_status()
# 如果没有指定保存路径,从 URL 中提取文件名
if save_path is None:
filename = extract_filename_from_url(image_url)
if not filename:
# 如果无法从 URL 提取文件名,使用默认名称
filename = f"file_{int(time.time())}.png"
# 根据文件类型确定保存目录
if is_video_file(filename):
save_dir = Path("videos")
file_type = "视频"
else:
save_dir = Path("images")
file_type = "图片"
save_path_str = str(save_dir / filename)
else:
save_path_str = save_path
filename = Path(save_path_str).name
if is_video_file(filename):
file_type = "视频"
else:
file_type = "图片"
# 确保保存路径是绝对路径
save_path_obj = Path(save_path_str).resolve()
# 确保目录存在
save_path_obj.parent.mkdir(parents=True, exist_ok=True)
# 保存文件
with open(save_path_obj, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
file_size = save_path_obj.stat().st_size
if not silent:
print(f"{file_type}已保存到: {save_path_obj}")
if file_size < 1024 * 1024: # 小于 1MB
print(f"文件大小: {file_size / 1024:.2f} KB")
else: # 大于等于 1MB
print(f"文件大小: {file_size / (1024 * 1024):.2f} MB")
return str(save_path_obj)
except requests.Timeout:
error_msg = f"下载文件超时(超过120秒)"
raise requests.RequestException(error_msg)
except requests.RequestException as e:
error_msg = f"下载文件失败: {e}"
if hasattr(e, 'response') and e.response is not None:
error_msg += f"\n响应状态码: {e.response.status_code}"
raise requests.RequestException(error_msg) from e
except Exception as e:
raise ValueError(f"保存文件失败: {e}") from e
def extract_and_download_image(
complete_url_result: Dict[str, Any],
save_path: Optional[str] = None,
silent: bool = False
) -> str:
"""
从完整 URL 响应结果中提取文件 URL 并下载(图片或视频)
Args:
complete_url_result: get_complete_url() 返回的结果
save_path: 保存路径(可选,如果不提供则自动根据文件类型保存到对应文件夹)
silent: 是否静默模式(不打印详细信息)
Returns:
保存的文件路径
Raises:
ValueError: 响应数据格式错误或缺少 data 字段
requests.RequestException: 下载失败
"""
# 检查响应格式
if not isinstance(complete_url_result, dict):
raise ValueError(f"响应数据格式错误,期望字典类型,实际: {type(complete_url_result)}")
# 提取 data 字段中的 URL
if 'data' not in complete_url_result:
raise ValueError(f"响应数据缺少 'data' 字段。响应内容: {json.dumps(complete_url_result, indent=2, ensure_ascii=False)}")
file_url = complete_url_result['data']
if not isinstance(file_url, str) or not file_url.startswith('http'):
raise ValueError(f"无效的文件 URL: {file_url}")
# 下载文件(图片或视频)
return download_image(file_url, save_path=save_path, silent=silent)
def crawl_single_file(
file_id: str,
silent: bool = False
) -> str:
"""
爬取单个文件(图片或视频)的完整流程
流程:
1. 生成挑战 payload
2. 验证 payload
3. 获取文件的完整 URL
4. 下载文件并保存到本地
Args:
file_id: 文件 ID(如 "16812449365937536")
silent: 是否静默模式(不打印详细信息)
Returns:
保存的文件路径
Raises:
requests.RequestException: 网络请求失败
ValueError: 数据格式错误或验证失败
"""
# 第一步:生成 payload
payload = generate_challenge_payload(silent=silent)
if not silent:
print("\n生成的 Payload:")
print(json.dumps(payload, indent=2, ensure_ascii=False))
# 第二步:编码 payload
payload_base64 = encode_payload(payload)
if not silent:
print("\nBase64 编码的 Payload:")
print(payload_base64)
# 第三步:验证 payload
verify_result = verify_payload(payload_base64, silent=silent)
if not silent:
print("\n验证结果:")
print(json.dumps(verify_result, indent=2, ensure_ascii=False))
# 第四步:获取完整 URL
complete_url_result = get_complete_url(file_id, silent=silent)
if not silent:
print("\n完整 URL 结果:")
print(json.dumps(complete_url_result, indent=2, ensure_ascii=False))
# 第五步:下载文件
if complete_url_result.get('status') == 200 and complete_url_result.get('data'):
saved_path = extract_and_download_image(complete_url_result, silent=silent)
file_type = "视频" if is_video_file(saved_path) else "图片"
if not silent:
print(f"\n{file_type}已成功保存到: {saved_path}")
return saved_path
else:
error_msg = "无法获取文件 URL,响应状态或数据异常"
if not silent:
print(f"\n警告: {error_msg}")
raise ValueError(error_msg)
if __name__ == '__main__':
# 示例用法
try:
file_id = "17805363362909568" # 文件 ID
saved_path = crawl_single_file(file_id)
print(f"\n✅ 爬取完成!文件已保存到: {saved_path}")
except Exception as e:
print(f"错误: {e}", file=sys.stderr)
import traceback
traceback.print_exc()
sys.exit(1)
最后更新: 2025-01-20


